Why Context Graphs?
AI agents need memory to be useful. But not all memory is created equal. This page explains why graph-structured memory — what we call a context graph — is fundamentally better for AI agents than flat document stores or vector databases alone.
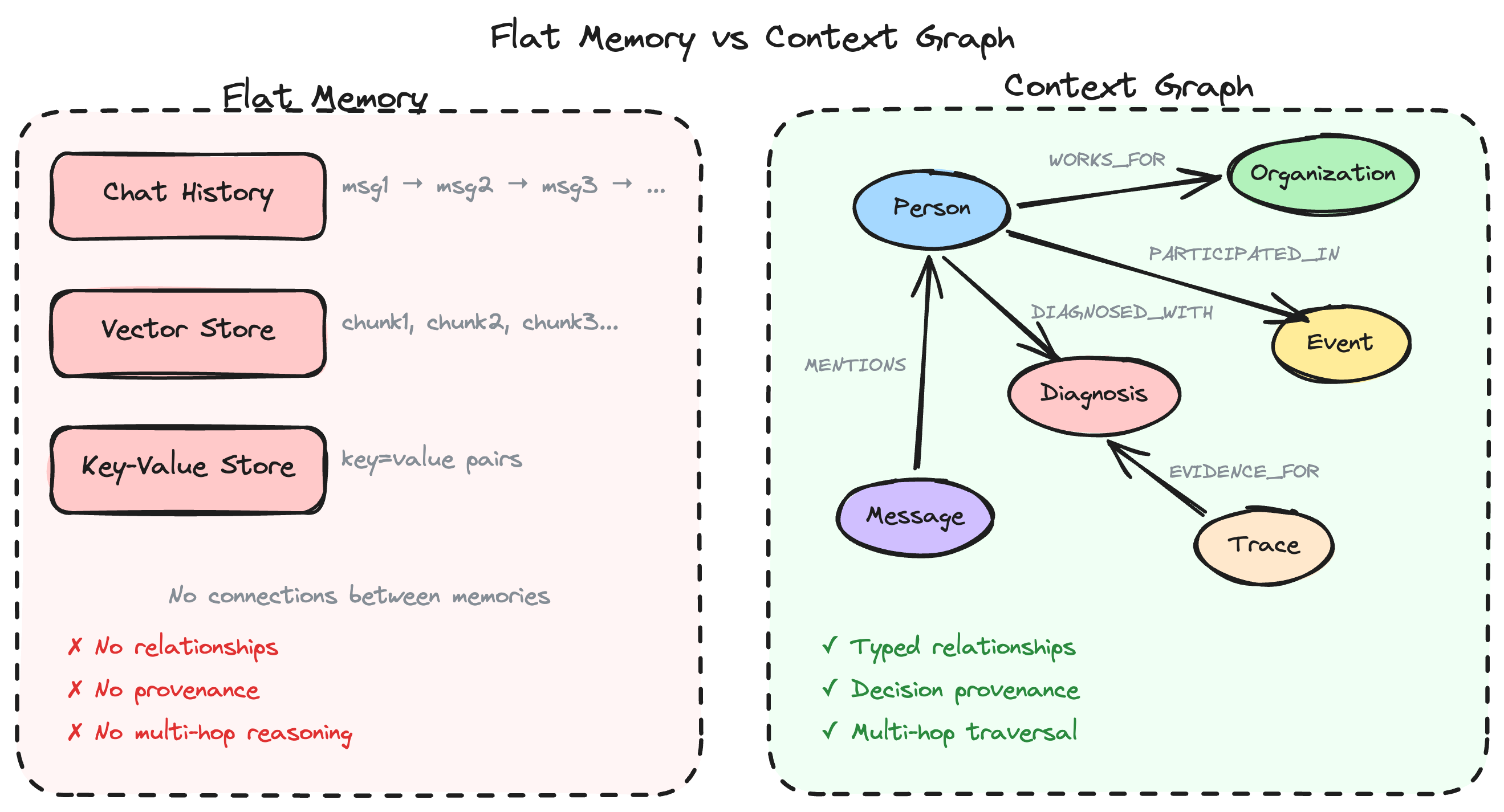
The Problem with Flat Memory
Most AI agent frameworks store memory as:
- Chat history: A linear sequence of messages
- Vector store: Chunks of text embedded and retrieved by similarity
- Key-value store: Simple facts stored as pairs
These approaches work for simple Q&A but break down when agents need to:
- Connect information across conversations — "The patient I discussed yesterday has a new diagnosis"
- Reason about relationships — "Which organizations are connected to this person?"
- Trace decisions back to evidence — "Why did the agent recommend this treatment?"
- Navigate multi-hop paths — "Find all patients treated by doctors who trained at this hospital"
Three Memory Types, One Connected Graph
A context graph combines three complementary memory layers in a single Neo4j database:
1. Knowledge Graph (Long-term Memory)
Entities (people, organizations, events, objects) and their relationships, structured using the POLE+O model:
- Person — People, patients, players, researchers
- Organization — Companies, hospitals, teams, agencies
- Location — Places, facilities, regions
- Event — Incidents, encounters, transactions
- Object — Documents, artifacts, instruments
Each domain extends these base types with domain-specific entities (e.g., Diagnosis, Treatment, Medication for healthcare).
2. Conversation History (Working Memory)
Multi-turn conversations stored as connected message nodes. Unlike flat chat logs, conversation nodes link to the knowledge graph entities they reference — so the agent can recall not just what was said but what it was about.
3. Decision Traces (Episodic Memory)
When an agent makes a decision (recommending a treatment, flagging a risk, choosing a data source), the reasoning chain is preserved as a trace:
DecisionTrace → HAS_STEP → TraceStep[1] → TraceStep[2] → ...
Each step records the thought, action, and observation. This provides auditable reasoning provenance — critical for high-stakes domains like healthcare and finance.
Why Graphs Beat Vectors
| Capability | Vector Store | Knowledge Graph |
|---|---|---|
| Semantic similarity search | Excellent | Good (with embeddings) |
| Exact relationship queries | Poor | Excellent |
| Multi-hop reasoning | Not possible | Native |
| Schema enforcement | None | Full |
| Explainable connections | No | Yes |
| Incremental updates | Requires re-embedding | Add nodes/edges |
The key insight: vectors find similar things; graphs find connected things. AI agents need both — similarity for discovery, structure for reasoning.
How create-context-graph Uses This
When you scaffold a project with create-context-graph, the generated application includes:
- Neo4j database with a domain-specific schema (entities, relationships, constraints)
- Agent tools that query the knowledge graph via Cypher
- Memory integration via
neo4j-agent-memoryfor conversation persistence - Decision trace storage for reasoning provenance
- Interactive visualization showing the graph structure and agent queries in real-time
The agent doesn't just retrieve documents — it navigates a structured knowledge space, following relationships and building context from connected entities.
Further Reading
- How Domain Ontologies Work — How entity schemas drive the entire application
- Three Memory Types — Deep dive into the memory architecture
- Your First Context Graph App — Build one and see for yourself